Folgen Sie Subraum Transmissionen auch gerne auf Social Media:
Die nächste Generation von KI-gestützten Audio-Modellen: Revolution in der Sprachverarbeitung
Die neuen Text-to-Speech-Modelle können nicht nur sprechen, sondern auch gezielt Emotionen und Tonalitäten wiedergeben.
Einleitung und Kontext
Die Interaktion mit Künstlicher Intelligenz (KI) verändert sich rasant. Während textbasierte KI-Agenten in den letzten Jahren erhebliche Fortschritte gemacht haben, bleibt die natürliche, gesprochene Sprache eine der intuitivsten und menschlichsten Formen der Kommunikation. Um diesen nächsten Entwicklungsschritt zu ermöglichen, wurden von OpenAI neue KI-Modelle für Speech-to-Text (STT) und Text-to-Speech (TTS) vorgestellt.
Diese neuen Modelle setzen neue Maßstäbe in der Genauigkeit und Flexibilität der Spracherkennung und -synthese. Besonders für Branchen wie den Kundenservice, die Transkription von Meetings oder die Erstellung natürlicher Sprachassistenten verspricht diese Technologie einen signifikanten Mehrwert. Darüber hinaus erlaubt sie erstmals eine detaillierte Steuerung der Sprachweise eines KI-Agents, was völlig neue Anwendungsmöglichkeiten eröffnet.
Doch welche technischen Fortschritte ermöglichen diese neue Generation von Audio-Modellen? Und welche Auswirkungen hat sie auf die KI-Landschaft?
Technische Analyse
Fortschritte in der Spracherkennung
Das Herzstück der neuen Speech-to-Text-Technologie sind die gpt-4o-transcribe und gpt-4o-mini-transcribe Modelle. Diese übertreffen ihre Vorgänger – einschließlich der weit verbreiteten Whisper-Modelle – in mehreren wichtigen Punkten:
- Geringere Word Error Rate (WER): Die Modelle minimieren Transkriptionsfehler durch optimierte Reinforcement-Learning-Techniken und verbesserte Trainingsmethoden.
- Höhere Robustheit in schwierigen Umgebungen: Hintergrundgeräusche, Akzente und unterschiedliche Sprechgeschwindigkeiten stellen weniger Probleme dar.
- Erweiterte Sprachunterstützung: Die Modelle wurden mit großen multilingualen Datensätzen trainiert, darunter das FLEURS-Benchmark-Set, das über 100 Sprachen umfasst.
Diese Verbesserungen resultieren aus einem mehrschichtigen Pretraining auf hochwertigen Audio-Datensätzen sowie einer gezielten Feinanpassung durch selbstlernende Algorithmen.
Entwickler können die Modelle über die Demo-Seite OpenAI.fm testen oder mit dem Agents SDK textbasierte Agenten in Sprachagenten verwandeln.
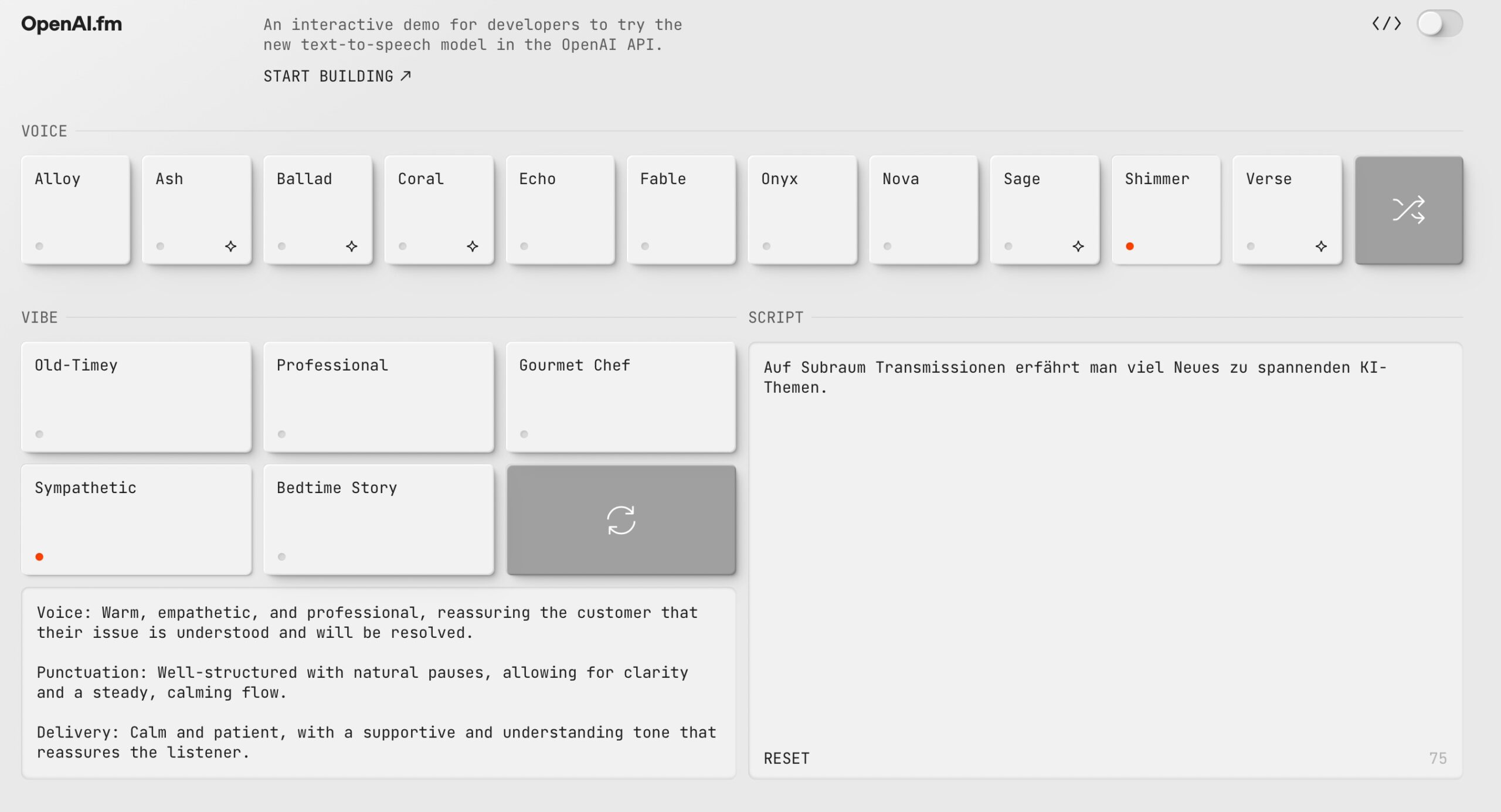
Fortschritte in der Sprachsynthese
Das neue gpt-4o-mini-tts Modell für Text-to-Speech geht einen Schritt weiter als frühere KI-Stimmen, indem es nicht nur den Inhalt, sondern auch die Intonation und Ausdrucksweise gezielt steuern lässt. Ein Entwickler kann beispielsweise anweisen: „Sprich wie ein empathischer Kundenservice-Agent“, um eine besonders einfühlsame Tonalität zu erzeugen.
Hierbei spielen fortschrittliche Distillationstechniken eine entscheidende Rolle: Große, ressourcenintensive Modelle dienen als Lehrer für kleinere, effizientere Versionen, die dennoch eine hohe Qualität beibehalten.
Anwendung und Nutzen
Die neuen Audio-Modelle eröffnen zahlreiche innovative Einsatzmöglichkeiten, insbesondere in Bereichen, in denen Sprachinteraktion eine zentrale Rolle spielt:
- Kundenservice & Support
- KI-Agenten können natürlicher mit Kunden sprechen und sogar emotionale Nuancen in ihrer Stimme einbauen.
- Reduzierung der Wartezeiten durch automatisierte, intelligente Sprachsysteme.
- Automatische Transkription & Dokumentation
- Verbesserte Genauigkeit bei Meeting-Protokollen und Interview-Transkriptionen.
- Bessere Verarbeitung schwieriger Akzente und Dialekte.
- Kreative Anwendungen
- Hochwertige, synthetische Sprecher für Hörbücher oder Podcasts.
- Neue Möglichkeiten für Voice-Over in Videos oder Computerspielen.
Trotz dieser Fortschritte gibt es auch Herausforderungen:
- Ethische Fragen der Stimmensynthese: KI-Stimmen könnten für betrügerische Zwecke missbraucht werden.
- Datenschutz & Sicherheit: Sprachdaten müssen sicher verarbeitet und gespeichert werden.
KI-Kategorien und Einordnung
Die neuen Audio-Modelle lassen sich in mehrere wichtige KI-Disziplinen einordnen:
- Maschinelles Lernen (ML):
Die Modelle werden auf riesigen Sprachdatensätzen trainiert, um Sprachmuster zu erkennen und zu reproduzieren. - Natürliche Sprachverarbeitung (NLP):
Sprachsynthese und -erkennung sind Teilbereiche der NLP, die sich mit der maschinellen Verarbeitung menschlicher Sprache befassen. - Reinforcement Learning (RL):
Durch belohnungsbasierte Optimierung wurden die neuen Speech-to-Text-Modelle deutlich verbessert. - Selbstüberwachtes Lernen (Self-Supervised Learning):
Die KI-Modelle lernen ohne menschliche Annotationen und können so effizient große Mengen an Sprachdaten verarbeiten.
Diese Kombination verschiedener Techniken sorgt für eine erhebliche Steigerung der Genauigkeit und Flexibilität der neuen Modelle.
Fazit und Ausblick
Mit diesen Fortschritten in der Sprach-KI bewegt sich die Technologie einen großen Schritt in Richtung natürlichere und intelligentere Sprachinteraktionen. Die neuen Modelle versprechen nicht nur genauere Transkriptionen, sondern auch emotional anpassbare KI-Stimmen, die für eine Vielzahl von Anwendungen genutzt werden können. Podcasting, Video-Voice-Over oder auch das Vorlesen von Websites um nur ein paar zu nennen.
Mögliche zukünftige Entwicklungen:
- Individuell anpassbare KI-Stimmen: Die Möglichkeit, eigene Stimmen hochzuladen und von der KI nachbilden zu lassen.
- Multimodale KI-Agenten: Die Kombination von Text, Sprache und Video, um interaktive, lebensechte KI-Assistenten zu erschaffen.
- Bessere Echtzeit-Verarbeitung: Schnellere und latenzarme Lösungen für Live-Interaktionen.
Die nächsten Jahre werden zeigen, wie sich diese Technologie weiterentwickelt – insbesondere im Spannungsfeld zwischen Innovationspotenzial und ethischer Verantwortung.
Einfache Zusammenfassung
Neue KI-Modelle für Spracherkennung und Sprachsynthese ermöglichen eine natürlichere und genauere Interaktion mit KI-Agenten. Die verbesserten Speech-to-Text-Modelle verstehen Sprache präziser – auch bei Akzenten oder Hintergrundgeräuschen. Die neuen Text-to-Speech-Modelle können nicht nur sprechen, sondern auch gezielt Emotionen und Tonalitäten wiedergeben.
Diese Technologie wird vor allem in Bereichen wie Kundenservice, automatischer Transkription und kreativen Medien eine wichtige Rolle spielen. Während die Entwicklung viele Chancen bietet, gibt es auch Herausforderungen wie Datenschutz und Missbrauchspotenzial.
Die Zukunft der KI-Sprachverarbeitung verspricht noch realistischere und interaktivere Anwendungen – vielleicht schon bald mit individuellen, anpassbaren KI-Stimmen für jeden Nutzer.
